Note
I've led this short workshop as part of Summer School of UDD CICS. I will soon compile the material here.
[Workshop] Orbitar Jupyter y Aterrizar en la Tierra: un viaje en Github hacia la Ciencia de Datos Práctica y Colaborativa.

Resumen
El curso es una intensiva sesión de trabajo diseñada para transformar la manera en que los estudiantes abordan la Ciencia de Datos: pasando de proyectos solitarios en Jupyter Notebook a un enfoque más colaborativo y práctico, listo para integrarse en entornos de software reales.
Se comienza con una introducción rápida a la Ciencia de Datos, enfatizando la importancia de estructuras de proyectos estandarizadas. Se explorará cómo Jupyter puede ser la puerta de entrada para análisis complejos, experimentación y desarrollo de productos de datos.
Luego se aborda cómo estructurar proyectos de Ciencia de Datos con metodologías estandarizadas como Cookiecutter para asegurar que sean mantenibles, replicables y escalables, adecuados para colaboración y uso en entornos de software real. No sólo se pondrá foco en el código, sino también en como trabajar con datos y modelos de machine learning.
A continuación, se exploran las tecnologías Git/GitHub, herramientas cruciales para el trabajo colaborativo. Los estudiantes aprenden sobre control de versiones (crear, clonar, commit, push, pull, branches), colaboración efectiva y la automatización de flujos de trabajo (github actions).
También se introducen temas clave para generar proyectos estructurados y listos para ser compartidos o desplegados, tales como entornos virtuales, devops, integración continua, colaboración open source, templates y contenedores, con el objetivo de establecer un camino de aprendizaje sugerido para el futuro.
Requisitos
Material
Introduccion
Profesor
- Subdirector de Alianzas con la Industria @ Instituto de Ciencia de Datos, Universidad del Desarrollo.
- Consultor Independiente: GeoVictoria - Defontana - Discolab - Subconscious.ai.
- Profesor en el Magíster de Data Science @ Universidad del Desarrollo.
- Ingeniero Eléctrico @ Universidad de Chile.

Empresas con las que he trabajado en la construcción de algún Producto de Datos
Ciencia de Datos
Ciencia de Datos es el estudio de extraer valor de los datos. Valor que puede ser en forma de insights (nuevas perspectivas) o conclusiones.
Data Science in Context: Foundations, Challenges, Opportunities.

The AI Hierarchy of Needs (Mónica Rogati, Hackernoon)
La triste realidad es que la mayoría de los proyectos de IA fracasan. Según una investigación de Gartner, solo el 15% de las soluciones de IA implementadas para 2022 serán exitosas, y serán muchas menos las que crearán un valor positivo en términos de ROI.
Why most AI implementations fail, and what enterprises can do to beat the odds.
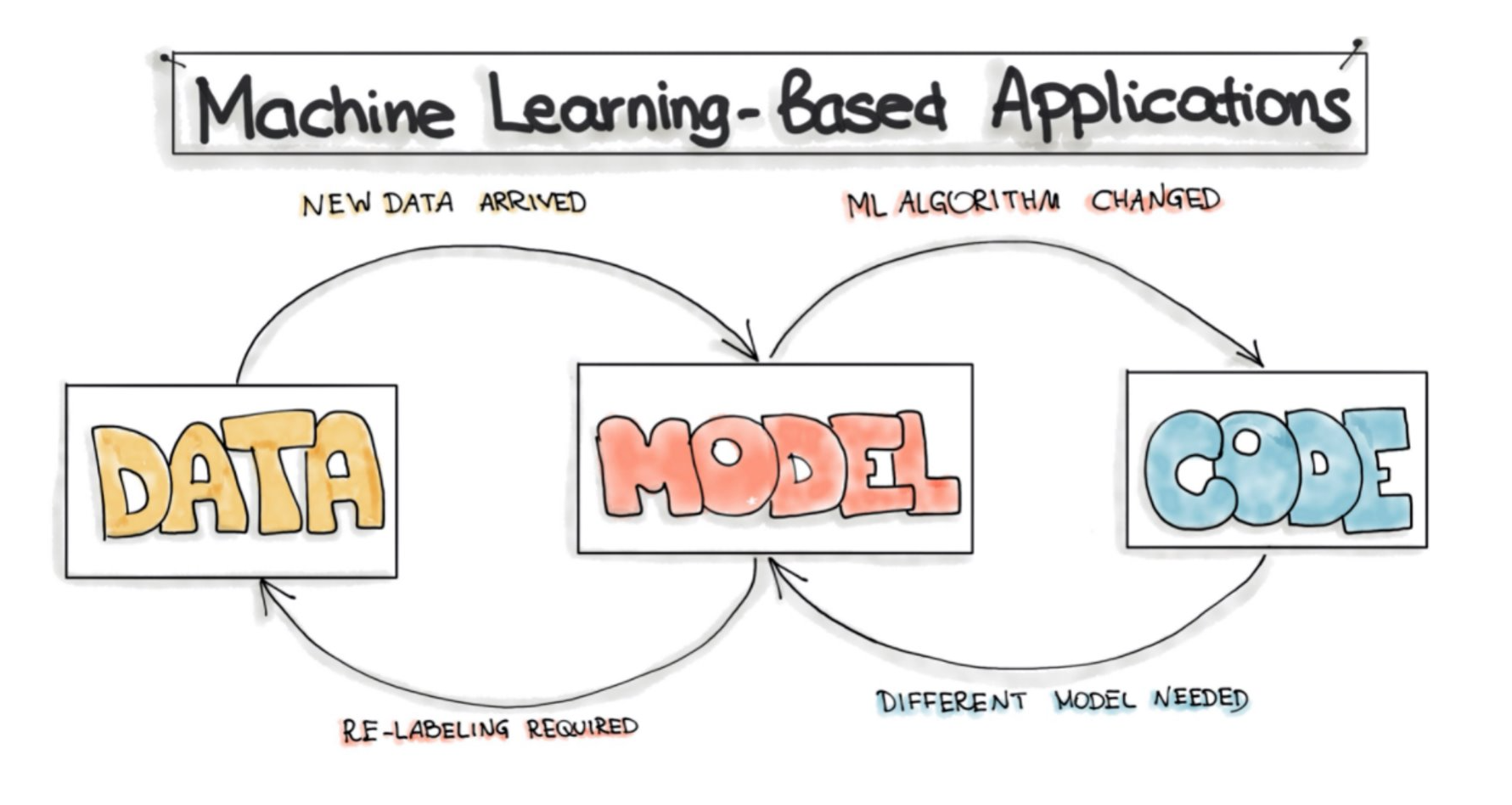
MLOps: Why you Might Want to use Machine Learning
Necesidades
La ejecución de un proyecto de Ciencia de Datos aborda todo el proceso de resolución de un problema: desde la recopilación y el procesamiento de datos, hasta el diseño del mejor método para resolver el problema y la implementación de una solución. Los problemas y los conjuntos de datos provienen de entornos realistas similares a los que nos podríamos encontrar en la industria, la academia o el gobierno. Por lo tanto, los proyectos por lo menos incluirán:
- Formulación de una pregunta para ser respondida por los datos.
- Limpieza y procesamiento de datos.
- Elegir y aplicar un modelo y/o método analítico adecuado al problema.
- Y comunicar los resultados a una audiencia no técnica.
Entre los desafíos que algo así plantea, encontramos que:
- Se debe atender el ciclo completo del proyecto: no sólo es mostrar el bello resultado final.
- En la mayoría de los casos trabajaremos en equipos, nunca solos.
- Será necesario responder con facilidad y rapidez por cada parte del proceso, ya que un grupo de investigadores/compañeros de equipo/stakeholders estarán presionando.
- Todo esto se desarrolla programando.
¡La calidad del código es muy importante! En Ciencia de Datos todo se reduce a prolijidad y reproducibilidad. La forma más fácil de alcanzar eso es mediante una estructura para el código o un cierto diseño del proyecto. Debemos empezar con una estructura limpia y mantenerla viva en todo el ciclo del proyecto.
Por qué es necesario esta metodología
El mundo te lo agradecerá
- Será mucho más fácil colaborar en equipo.
- Se podrá aprender más al analizar de forma más fácil el proceso que se sigue al construir proyectos.
- Todos podremos sentirnos más confiados sobre la veracidad de las conclusiones a las que lleguen los proyectos.
Tú te lo agradecerás
- ¿Había que usar
plot_figures.py.oldo eranew_figures01.pyonew_figures01_updated.py? - ¿Había que hacer el merge con la columna X antes de empezar o eso quedaba dentro de alguno de los notebooks
- ¿Cuál notebook iba primero, era “procesar datos” o “limpiar datos”?
- ¿De dónde fue que bajé los shapefiles para dibujar los mapas?
Cookiecutter
Estructura
Está basada en Cookiecutter Data Science pero simplifacada en el Template IDS Cookiecutter.
├── LICENSE
├── README.md <- The top-level README for developers using this project.
├── data
│ ├── external <- Data from third party sources.
│ ├── interim <- Intermediate data that has been transformed.
│ ├── processed <- The final, canonical data sets for modeling.
│ └── raw <- The original, immutable data dump.
│
├── models <- Trained and serialized models, model predictions, or model summaries
│
├── notebooks <- Jupyter notebooks. Naming convention is a number (for ordering),
│ the creator's initials, and a short `-` delimited description, e.g.
│ `1.0-jqp-initial-data-exploration`.
│
├── references <- Data dictionaries, manuals, and all other explanatory materials.
│
├── reports <- Generated analysis as HTML, PDF, LaTeX, etc.
│ └── figures <- Generated graphics and figures to be used in reporting
│
│
├── src <- Source code for use in this project.
│ ├── __init__.py <- Makes src a Python module
│ │
│ ├── data <- Scripts to download or generate data
│ │ └── make_dataset.py
│ │
│ ├── features <- Scripts to turn raw data into features for modeling
│ │ └── build_features.py
│ │
│ ├── models <- Scripts to train models and then use trained models to make
│ │ │ predictions
│ │ ├── predict_model.py
│ │ └── train_model.py
│ │
│ └── visualization <- Scripts to create exploratory and results oriented visualizations
│ └── visualize.py
├── requirements.txt <- The requirements file for reproducing the analysis environment, e.g. generated with `pip freeze > requirements.txt`
Los datos son inmutables
- Nunca se debe editar la data cruda (raw data).
- Nunca se debe editar manualmente.
- Nunca se debe editar en Excel.
- Nunca se debe editar manualmente.
- Nunca se debe sobre-escribir raw data.
- No se debe guardar múltiples versiones de un archivo de raw data
- El código que se escriba debe mover la data cruda por medio de un pipeline hacia el análisis final.
- Cualquier persona debería poder reproducir los resultados sólo teniendo la carpeta
data/rawy el código en la carpetasrc. - Si los datos son inmutables entonces no necesita tener el mismo control de versiones que el código. Por defecto el directorio data debería estar incluido en el archivo
.gitignore.
Los notebooks son para exploración y comunicación
- Son muy buenos para análisis exploratorio pero no tan buenos para reproducir de forma efectiva ese análisis.
- Se sugiere trabajar en carpetas dentro del directorio notebooks.
- Se sugiere seguir una convención para nombrar los archivos:
<step>-<ghuser>-<description>.ipynb. Ejemplo:03-aastroza-visualize-distributions.ipynb - Hay que hacer refactorizaciones de las partes claves. No se debe repetir el código de la misma tarea en diferentes notebooks. Si el código es útil, escribanlo siempre a la carpeta
src. - Por ejemplo: si es una tarea de preprocesamiento de datos, hay que poner el pipeline en
src/data/make_dataset.pyy cargar datos desdedata/interim.
Git/Github
Aprenderemos Github usando este Template. Hay que abrir este enlace y seguir las instrucciones.
Git es un software de control de versiones diseñado por Linus Torvalds, pensando en la eficiencia, la confiabilidad y compatibilidad del mantenimiento de versiones de aplicaciones cuando estas tienen un gran número de archivos de código fuente. Su propósito es llevar registro de los cambios en archivos de computadora incluyendo coordinar el trabajo que varias personas realizan sobre archivos compartidos en un repositorio de código.
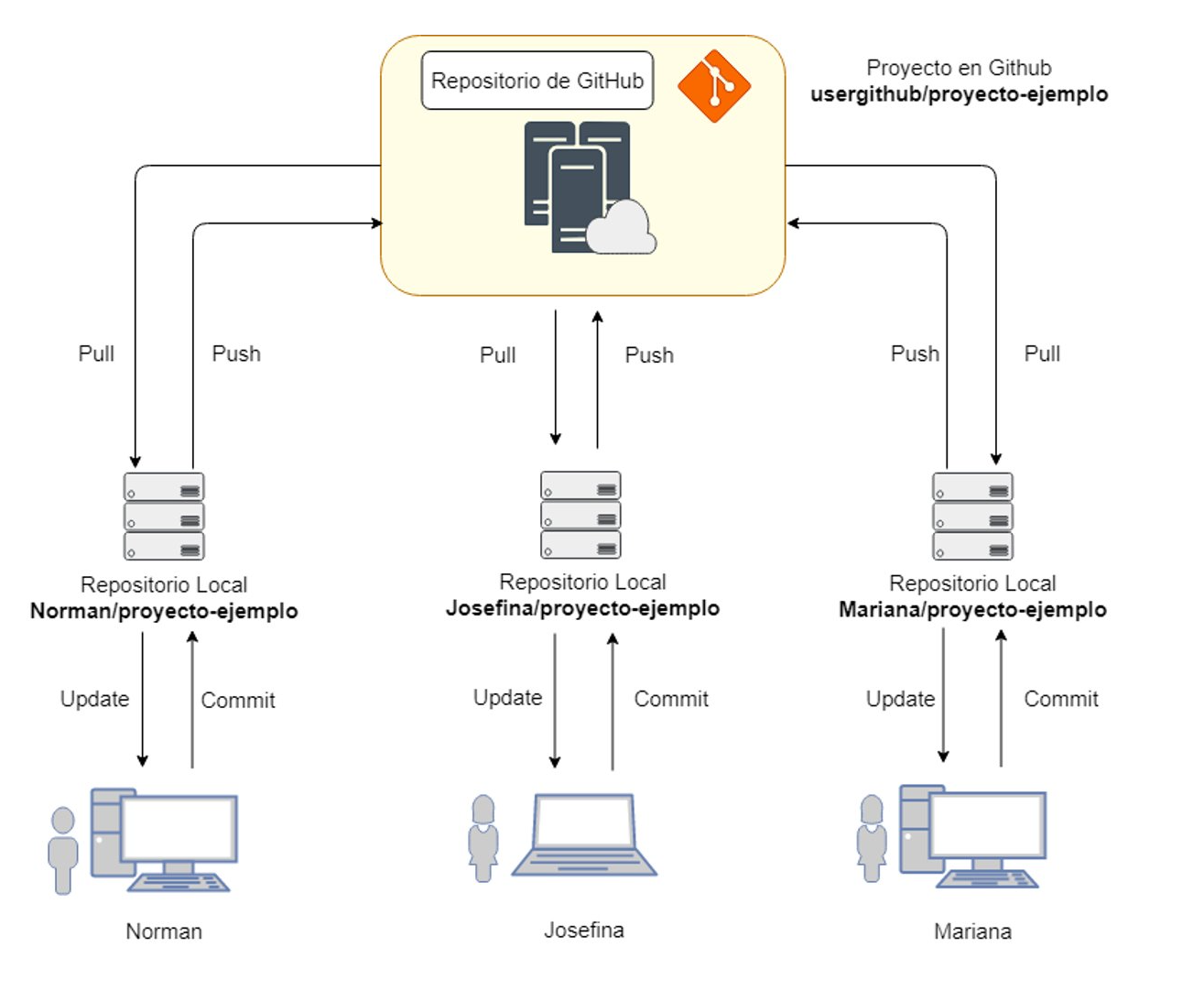
Norman Perrin, Introducción a Git y Github
Algunos tips de Git for Data Science:
No agregues los datasets
Git es un sistema de control de versiones diseñado para servir a los desarrolladores de software. Cuenta con excelentes herramientas para manejar el código fuente y otros contenidos relacionados como configuración, dependencias, documentación. No está pensado para datos de entrenamiento. Punto. Git es solo para código.
En el desarrollo de software, el código es rey y todo lo demás sirve al código. En la ciencia de datos, esto ya no es el caso y existe una dualidad entre datos y código. No tiene sentido que el código dependa de los datos tanto como no tiene sentido que los datos dependan del código. Deben estar desacoplados y aquí es donde el modelo de desarrollo de software centrado en el código te falla. Git no debería ser el punto central de verdad para un proyecto de ciencia de datos.
Hay extensiones como LFS que se refieren a conjuntos de datos externos desde un repositorio git. Aunque cumplen un propósito y resuelven algunos de los límites técnicos (tamaño, velocidad), no resuelven el problema central de una mentalidad de desarrollo de software centrada en el código arraigada en git.
Siempre tendrás conjuntos de datos flotando en tu directorio local, sin embargo. Es bastante fácil agregarlos accidentalmente al escenario y hacer un commit de ellos si no tienes cuidado. La forma correcta de asegurarte de que no necesitas preocuparte por los conjuntos de datos con git es usar el archivo de configuración .gitignore. Agrega tus conjuntos de datos o la carpeta de datos a la configuración y no mires atrás.
Ejemplo:
# ignore archives
*.zip
*.tar
*.tar.gz
*.rar
# ignore dataset folder and subfolders
data/
No agregues tus passwords/keys
Esto debería ser obvio, pero los constantes errores en el mundo real nos demuestran que no lo es. No importa si el repositorio es privado. En ninguna circunstancia se debe hacer un commit de ningún nombre de usuario, contraseña, token de API, código clave, certificados TLS, o cualquier otro dato sensible en git.
Incluso los repositorios privados son accesibles por múltiples cuentas y también se clonan en múltiples máquinas locales. Esto le da al hipotético atacante exponencialmente más objetivos. Recuerda que los repositorios privados también pueden volverse públicos en algún momento.
Desacopla tus secretos de tu código y pásalos usando el entorno en su lugar. Para Python, puedes usar el común archivo .env, que contiene las variables de entorno, y el archivo .gitignore, que asegura que el archivo .env no se envíe al repositorio remoto de git. Es una buena idea también proporcionar el .env.template para que otros sepan qué tipo de variables de entorno espera el sistema.
.env:
API_TOKEN=98789fsda789a89sdafsa9f87sda98f7sda89f7
.env.template:
API_TOKEN=
.gitignore:
.env
hello.py:
from dotenv import load_dotenv
load_dotenv()
api_token = os.getenv('API_TOKEN')
Esto todavía requiere algo de copiar y pegar manualmente para cualquiera que clone el repositorio por primera vez. Para una configuración más avanzada, hay herramientas encriptadas y con acceso restringido que pueden compartir secretos a través del entorno, como Doppler
Note
Si ya has enviado tus secretos al repositorio remoto, no intentes arreglar la situación simplemente borrándolos. Es demasiado tarde ya que git está diseñado para ser inmutable. Una vez que el gato está fuera de la bolsa, la única estrategia válida es cambiar las contraseñas o desactivar los tokens.
Realiza commits pequeños con descripciones claras
Los usuarios inexpertos a menudo caen en la trampa de hacer commits enormes con descripciones sin sentido. Una buena regla general para cualquier commit en git es que solo debe hacer una cosa. Arreglar un bug, no tres. Resolver un problema, no doce. Recuerda que los problemas a menudo pueden dividirse en partes más pequeñas también. Cuanto más pequeño puedas hacerlo, mejor.
La razón por la que usas el control de versiones es para que otra persona pueda entender lo que ha sucedido en el pasado. Si tu commit arregla doce bugs y la descripción dice "Modelo arreglado", su valor es cercano a cero dos meses después. El commit solo debe hacer una cosa y solo una cosa. La descripción debe comunicar lo que esa cosa fue. No necesitas hacer descripciones extensas si los commits son pequeños. De hecho, ¡una descripción larga para un mensaje de commit implica que el commit es demasiado grande y deberías dividirlo en partes más pequeñas!
Ejemplo de un mal repositorio

Ejemplo de un buen repositorio

No le tengas miedo a las ramas y pull requests
El uso de ramas y, en especial, de pull requests son técnicas ligeramente más avanzadas y no son del agrado de todos, pero si tu proyecto de ciencia de datos está maduro, en producción y constantemente manejado por muchas personas diferentes, los pull requests podrían ser justo lo que falta en tu proceso.
Cuando creas un nuevo repositorio git, este comienza con una única rama llamada main (o master). La rama main se considera como la verdad central. Crear ramas significa que te desviarás temporalmente para crear una nueva característica o una corrección a una antigua. Mientras tanto, alguien más puede trabajar en paralelo en su propia rama. Esto se conoce comúnmente como flujo de trabajo de rama de características.
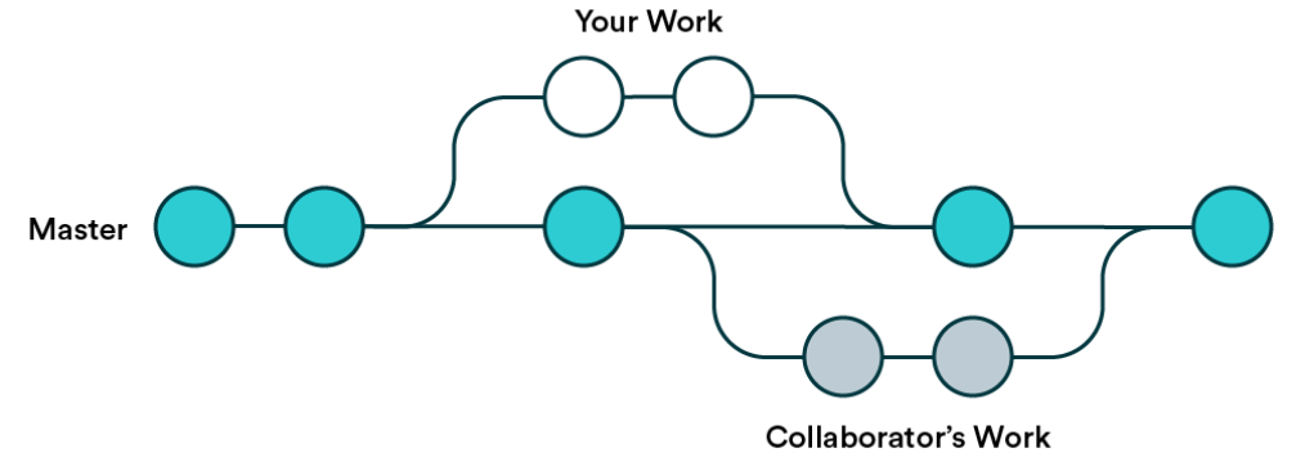
La idea con las ramas es eventualmente fusionarse de nuevo a la rama main y actualizar la verdad central. Aquí es donde entran en juego los pull requests. Al resto del mundo no le importan tus commits en tu propia rama, pero fusionarse a main es cuando tu rama se convierte en la última verdad. Ese es el momento de hacer un pull request.
Los pull requests no son un concepto de git, sino de GitHub. Son una solicitud para hacer de tu rama la nueva verdad central. Mediante el pull request, otros usuarios revisarán tus cambios antes de que se les permita convertirse en la nueva verdad central. GitHub ofrece excelentes herramientas para hacer comentarios, sugerir modificaciones, señalar aprobaciones y finalmente aplicar la fusión automáticamente.
[Opcional] No agregues los outputs de los Jupyter Notebooks
Los notebooks son geniales porque te permiten no solo almacenar código, sino también los resultados de las celdas, como imágenes, gráficos y tablas. El problema surge cuando haces commit y push del notebook con sus salidas a git.
La forma en que los notebooks serializan todas las imágenes, gráficos y tablas no es atractiva. En lugar de archivos separados, codifica todo como sintaxis JSON en el archivo .ipynb. Esto confunde a git.
Git piensa que la sintaxis JSON son igual de importantes que tu código. Las tres líneas de código que cambiaste se mezclan con las tres mil líneas que se cambiaron en la sintaxis JSON. Intentar comparar las dos versiones se vuelve inútil debido a todo el ruido adicional.

Se vuelve aún más confuso si hemos cambiado algo de código después de que se generaron las salidas. Ahora el código y las salidas que están almacenadas en el control de versiones ya no coinciden.
Hay dos opciones a nuestra disposición:
- Puedes borrar manualmente las salidas desde el menú principal (Celdas -> Toda la Salida -> Borrar) antes de crear tu commit en git.
- Puedes configurar un hook de pre-commit para git que borre las salidas automáticamente.
Trataremos de implementar esta opción #2, ya que los pasos manuales que necesitas recordar están destinados a fallar eventualmente.
Los futuros destinos de este viaje
Open Source
Making a pull request to an open-source project
Data Drift / Concept Drift
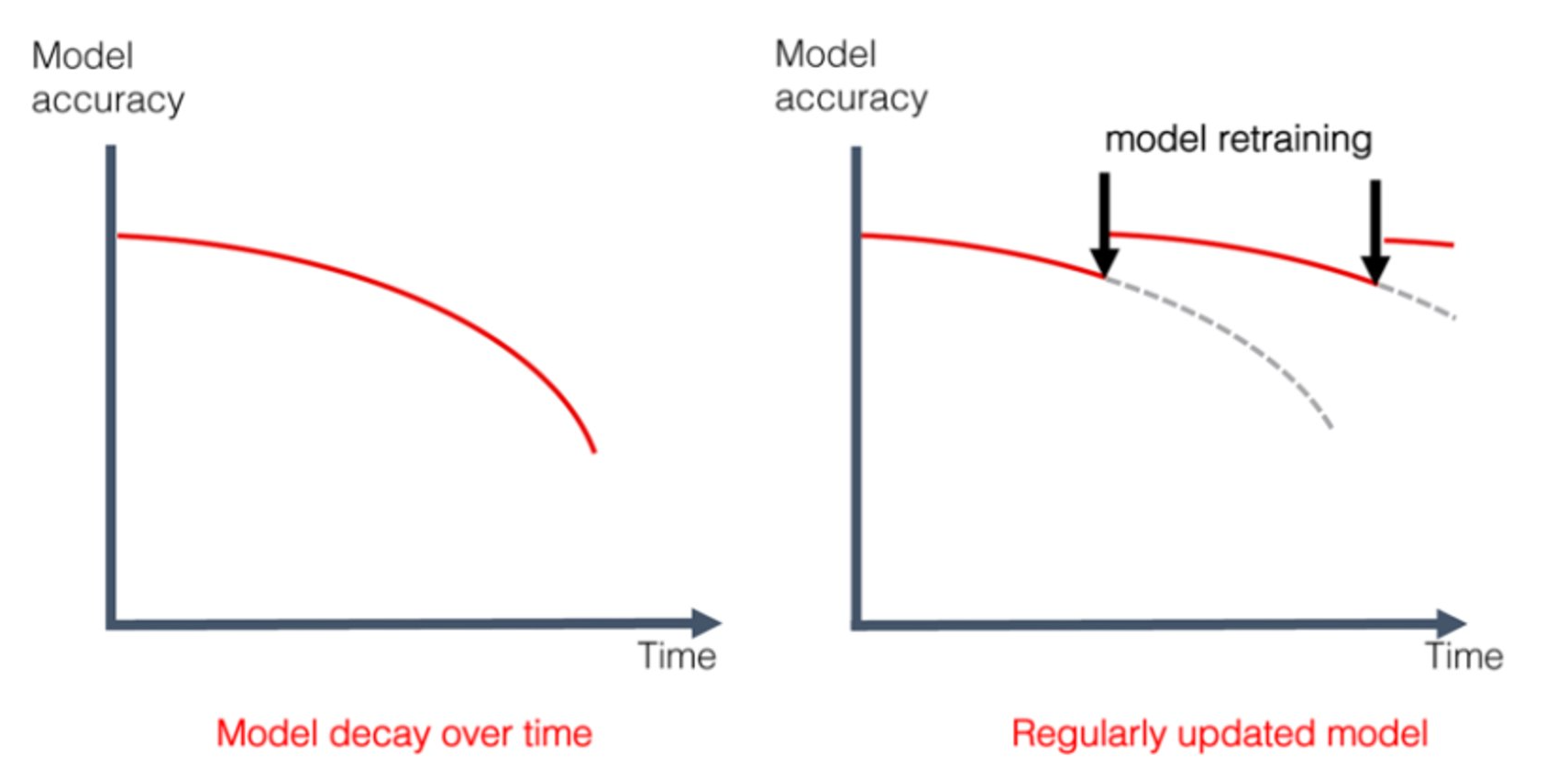
Machine Learning in Production: Why You Should Care About Data and Concept Drift
Devops/MLOps/LLMOps

Advanced Model Deployments (Hannes Hapke y Catherine Nelson)
Contenedores
Otras formas de contar esta historia
